
Graph databases utilize network-style data storage to connect various bits of information. As opposed to typical relational databases that store every data attribute within a formatted table restriction, graph structures have the benefit and versatility to map limitless relationships across considerable datasets. Effectively utilizing these connections allows extrapolation of additional context not always evident in isolated attributes. While relational databases still serve an important purpose for normalized data storage and reporting purposes, graph databases present unique analytical advantages in tracing relationships for modern, intricate data analysis. Several high-quality graph database management system solutions now exist to take advantage of these networked insights. I outline the top 10 graph database systems below based on capabilities, scalability, developer community, and enterprise reliability per testing across annual release cycles. DBAs need to evaluate their data relationship mapping and performance requirements as part of regular reporting to determine which solution warrants deeper investigation for potential utilization.
1. Neo4j
As one of the original and most proven graph database management systems, Neo4j pioneered connected data relationship mapping as a commercial product nearly two decades ago. The underlying graph query language, Cypher, provides an SQL-like framework optimized specifically around visualizing and extrapolating insights from these relationship graphs. As Neo4j continues expanding native analytic functions and scalability in the cloud, the graph database maintains widespread use across organizations seeking deeper contextual analysis of complex modern data structures with the support of the industry’s largest graph database community.
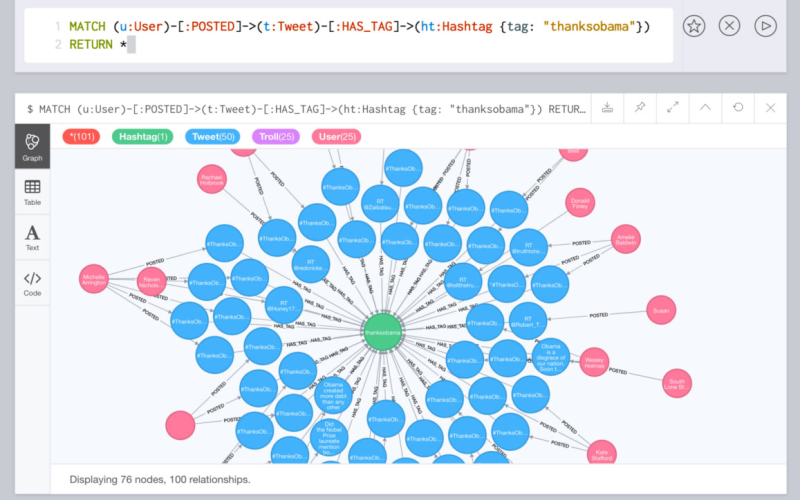
2. GraphDB
Ontotext created GraphDB to focus on semantic representations across interconnected ontologies. As a graph database built to ingest myriad entity types and map limitless conceptual relationships through adaptive linking predicates, GraphDB suits knowledge graph development with versatile data modeling capabilities that encompass extensible ontology mapping. Consequently, the graph database carries substantial capabilities in integrating disparate datasets into unified relationship mapping visualizations for contextual analysis and extrapolation.
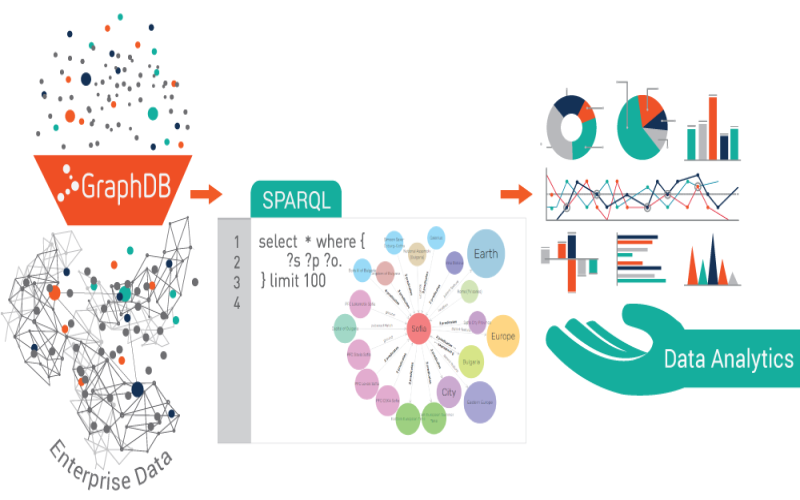
3. ArangoGraph
ArangoDB, the company behind ArangoGraph, sought initially to bridge capabilities from across database models, including graph, document and search functionalities, into an integrated solution. As graph workloads grew more complex, ArangoGraph became the fully graph-focused derivative database option. It brings graph processing performance through the native integration of popular graph modeling frameworks. Additional distributed cluster capabilities and integrations further ArangoGraph’s versatility in distributed relationship analysis across cloud or on-premises environments.
4. RedisGraph
As a graph module within Redis Labs’ in-memory data structure server, RedisGraph carries the brand familiarity and high-performance expectations associated with Redis into the graph database landscape. By combining the typical high-speed in-memory processing advantages while retaining data persistence through the incorporated Redis platform, RedisGraph suits real-time graph workloads needing instant data context extrapolation. As the graph module continues maturation to general availability in the Redis data structure server, RedisGraph warrants deeper investigation for low latency graph analysis use cases.

5. Dgraph
Dgraph, the native graph database option by the Dgraph Labs team, arrived at graph databases with a focus on only horizontally scalable implementations in distributed environments from the initial open-source release. As Dgraph further extends transactional, operational, and real-time graph querying capabilities through ongoing performance refinements, Dgraph continues gaining additional capabilities suited for web scale production graph workloads requiring minimal latency. The fully managed Dgraph cloud now further simplifies these scalable graph database deployments.

6. TerminusDB
Taking a uniquely inclusive strategy around data modeling benefits across the database landscape, TerminusDB combines document, graph, and query advantages within a singular managed platform. Expansive modeling flexibility through the WOQL query language supporting JSON, XML, and RDF data inputs complements versatile visual graph representations. As the TerminusDB environment continues maturing since the initial launch by TerminusDB, the unified database warrants consideration where varied workloads and skill sets interact across an organization’s data analytics needs.

7. Amazon Neptune
The fully managed graph database option from Amazon Web Services, Amazon Neptune gives AWS clients added productivity through a highly scalable graph engine supporting billions of relationships while handling query flexibility through both Gremlin and SPARQL. While still maturing the initial Neptune graph workload-focused capabilities since launch, expanded integrations across other AWS analytics offerings provide additional means to extrapolate insights through automated graph visualizations. For AWS-centric organizations lacking specialized graph database administration skills, Neptune warrants consideration as a low administrative burden graph database foundation.

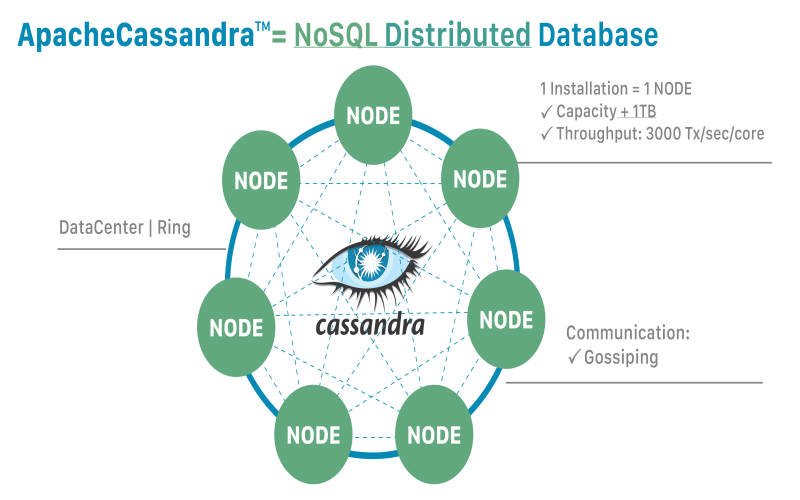
8. Apache Cassandra – Linear Scalability Out Of The Box
Originally developed to meet Facebook’s expanding data volumes, Apache Cassandra immediately set out to solve immense, distributed database storage and access with automatic scalability. The linear scalability model continues to prove effective through Cassandra’s maturity via the open-source Apache community. Consequently, Cassandra warrants consideration where transactional or analytical workloads require adaptable scaling without schema restrictions across potentially thousands of data nodes. While lacking native graph database capabilities, Cassandra backends high-velocity graph computing solutions that require nimble storage expansion.
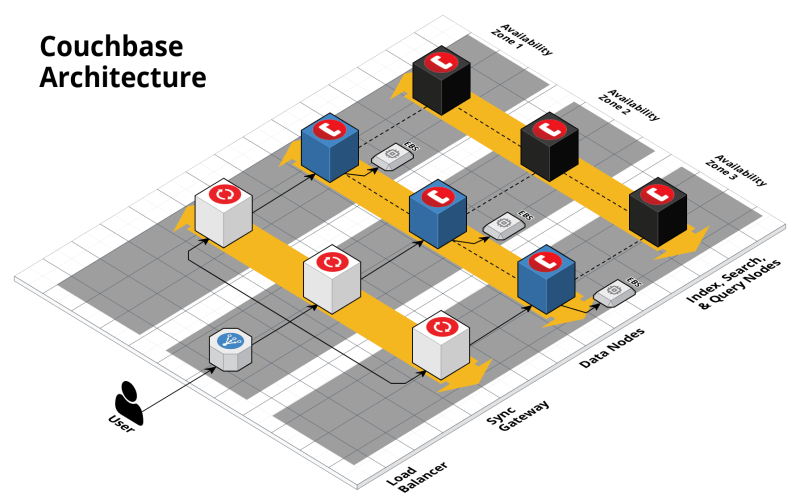
9. Couchbase Server – Highly Scalable Architecture With Low Latency
Taking document database capabilities to substantially larger data volumes, Couchbase set out to build enterprise-class database infrastructure combining high availability, exceptional scalability, and sustained low latency performance. The integrated analytics query engine further allows organizations to extrapolate live business insights without disrupting operational workloads. Accordingly, Couchbase Server suits demanding enterprise environments where relational database limitations require rethinking foundational data storage and real-time analysis approaches at web scales.
10. DynamoDB – Fully Managed NoSQL Database Service
The fully managed non-relational database option from Amazon Web Services, DynamoDB enables server-less database functionality to autoscale storage and maintain performance based solely on application needs at any data size. Organizations already committed to cloud analytics can benefit greatly from DynamoDB’s versatile document and key-value data modeling capabilities to expand previously bounded datasets for deeper insights. While still developing more complex query potential, DynamoDB’s operational analytics possibilities continue growing across integrated AWS offerings enabling live contextual analysis through dynamic visual graph representations.
















{kind=link}