
Machine learning is an interesting area.oneof the interesting fact about it is the Machine Learning algorithmic rule. This rule says that there is no approach or one answer that caters to all of your issues. However, you’ll invariably choose an algorithm that just about solves your problems so you can customize it to form one excellent solution for your problem. Here we tend to be stating some factors which will assist you to slim down your list of machine learning algorithm options.

Kinds Of Machine Learning Algorithms
Machine learning Algorithms Will Be Categorized Generally Into 3 Main Categories:
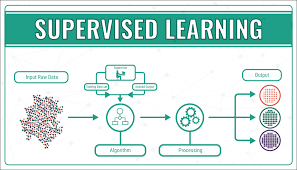
Supervised Learning
In supervised learning, the algorithmic rule builds a model data that has labels for each input and output. Information classification and regression algorithms are thought-about supervised learning.
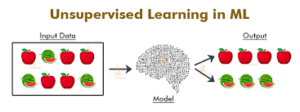
Unsupervised Learning
In unsupervised learning, the algorithm builds a model on data that solely has the input options however no labels for output. The models then are trained to appear for a few structures inside the data. Agglomeration and segmentation are samples of unsupervised learning algorithms.
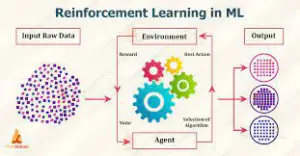
Reinforcement Learning
In Reinforcement learning, the model learns to perform a task by playing a group of actions and choices it improvises by itself so learn from the feedback of these actions associate degreed calls. Monte Carlo is an example of reinforcement learning algorithmic rules.
Vital data regarding your information can assist you to build an initial decision on an algorithm

The Scale Of Data
Some algorithms perform higher with larger data than others. For example, for little coaching datasets, algorithms with high bais/ low variance classifiers will work better than low bias/ high variance classifiers. So, for small training data, Naïve Thomas Bayes will perform better than kNN.
The characteristics Of Data
this implies however your data is formed. Is your data linear? Then perhaps a linear model can work it best, resembling regressions — linear and logistical — or SVM (support vector machine). However, if your data is a lot of complexes, then you would like an algorithmic rule like a random forest.
Here are some necessary concerns whereas selecting an algorithm.
1. Size Of The Coaching Data
It’s typically counseled to collect an honest quantity of knowledge to induce reliable predictions. However, much another time, the supply of data may be a constraint. So, if the coaching information is smaller or if the dataset incorporates a fewer number of observations and a better number of options like genetic science or matter data.
If the training data is sufficiently massive and therefore the number of observations is higher as compared to the number of features, one will opt for low bias/high variance algorithms like KNN, call trees, or kernel SVM.

2. Exactness Of The Output
The accuracy of a model suggests that the operation predicts a response value for an offer observation, which is on the brink of verita y response value for that observation. An extremely explainable algorithmic rule (restrictive models like Linear Regression) means one will simply perceive however someone predictor is related to the response whereas the versatile models give higher accuracy at the value of low interpretability.
An illustration of the trade-off between Accuracy and Interpretability, victimization completely different applied mathematics learning methods. (Source)

3. Speed Or Coaching Time
Higher accuracy usually means higher training time. Also, algorithms need longer to coach on large coaching data. In real-world applications, the selection of algorithmic rules is driven by these 2 factors predominantly.
Algorithms like Naïve Thomas Bayes and Linear and logistical regression are straightforward to implement and fast to run. Algorithms like SVM, which involve standardization of parameters, neural networks with high convergence time, and random forests, would like a great deal of your time to coach the data.

4. One-Dimensionality
Several algorithms work on the idea that categories will be separated by a line (or its higher-dimensional analog). Examples embrace logistic regression and support vector machines.

5. Variety Of Options
The dataset may have an oversized number of features that will not all be relevant and significant. For a precise sort of data, resembling genetic science or textual, the number of features will be large compared to the number of knowledge points. an oversized number of features will hamper some learning algorithms, creating coaching time unfeasibly long. SVM is best suited just in the case of data with large feature houses and lesser observations. PCA and have choice techniques ought to be accustomed cut back spatial property and choosing necessary features.
















{kind=link}