
We are totally dependent on the Internet for every little thing such as searching for information to maintaining the business. We can’t imagine our lives, not even one day without the Internet. To make us get connected with the Internet and solve our issues we need an interface which is the browser. It helps us to connect, interact with the Internet for all the different uses. We use search engines to search for the information. There are many search engines in the market such as Google, Yahoo, Bing, etc. But Google is known to be the mostly used and the popular search engine ever. There are thousands of files stored and managed by the Google. It provides each and every possible information we search for. Thus it maintains huge no of files. Ever wondered how is this possible, how can it manage such a large group of files and allows us to have access to them? The one solution for all of these queries is Google File System.

For its use, Google has developed GoogleFS, which is a proprietary distributed file system. With the help of large clusters of hardware components, it provides reliable and efficient access to data for the users. In 2010, codenamed Colossus which is the new version of the Google File System is released with additional functionalities.
To accommodate and fulfil the expanding requirements of the data processing, Google File System (GFS) is developed which is also considered as the scalable distributed file system (DFS) created by Google Inc. To the connected nodes and the large networks, performance, availability, reliability, fault tolerance, scalability is provided by the GFS.
Using the hardware components of low cost, several storage systems of different purposes are included in the GFS. Different storage requirements and data use are to be accommodated by the optimized Google’s elements, such as its search engine, which is used to store and retrieve large amounts of data from its file system.
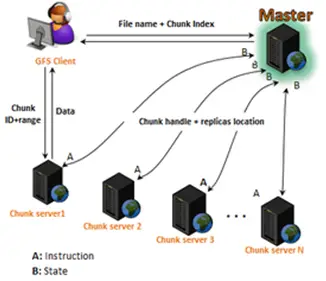
To engage and fulfil the needs of the multiple clients systems continuously, a single master called the GFS node cluster is provided with multiple chunk servers. On local disks, these chunk servers store data as Linux file. The data that is stored is replicated three times in the network as it is divided into large chunks at least of 64 MB.
Path names are used to identify the files that are stored in directories in a hierarchical way. The master that monitors, controls, interact with the status updates through messages of timed heartbeat of each chunk server is Metadata. Mapping information, accessing of control data, namespace, etc. are the information provided by the Metadata.
Features such as High aggregate throughput, High availability, efficient and automatic recovery of the data, locking and management, replication of critical data, fault tolerance, etc are provided by the GFS. More than 300 Tera bytes of storage capacity and 1000 nodes are present in the largest GFS clusters. Hundreds of clients can access this data continuously.















{kind=link}