
Data systems are just like the building blocks of computer science and software program development, playing a critical role in manipulating data successfully. They’re like the prepared cabinets in a library, ensuring smooth access to books. In this blog post, we’re going to study better the pinnacle ten fact structures that each programmer must get comfortable with. These information systems act like reachable tools in a programmer’s toolkit, helping to sort, seek, and control data correctly. By knowing them, you’ll be better geared up to resolve complicated issues, write more excellent green code, and craft elegant solutions. So, let’s dive into this exciting international of statistical structures!
1. Arrays
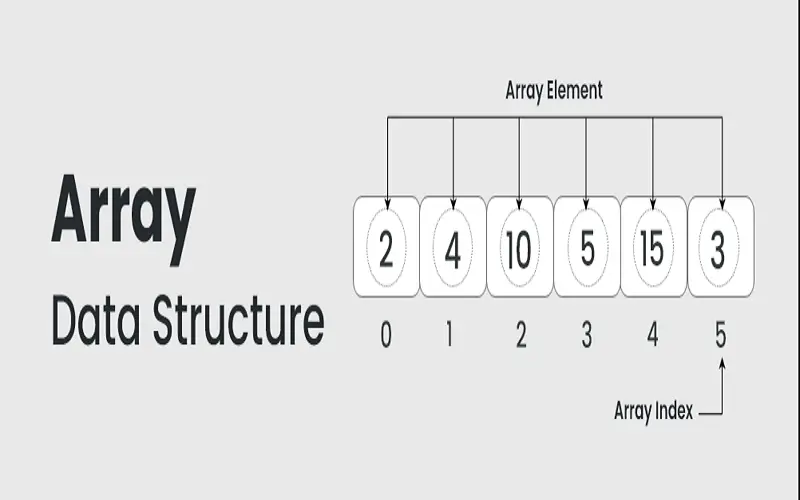
Arrays are a fundamental and widely used data structure in computer science. They are valued for the ability to store elements of the same data type in adjacent memory locations, enabling efficient indexing and random access operations. Arrays find application in a broad spectrum of scenarios, serving as foundational components of data storage and manipulation. These versatile structures are commonly employed in various tasks, including managing lists of objects. Their simplicity and efficiency as critical components for implementing dynamic programming algorithms make arrays an indispensable tool for programmers and developers in various fields.
2. Linked Lists
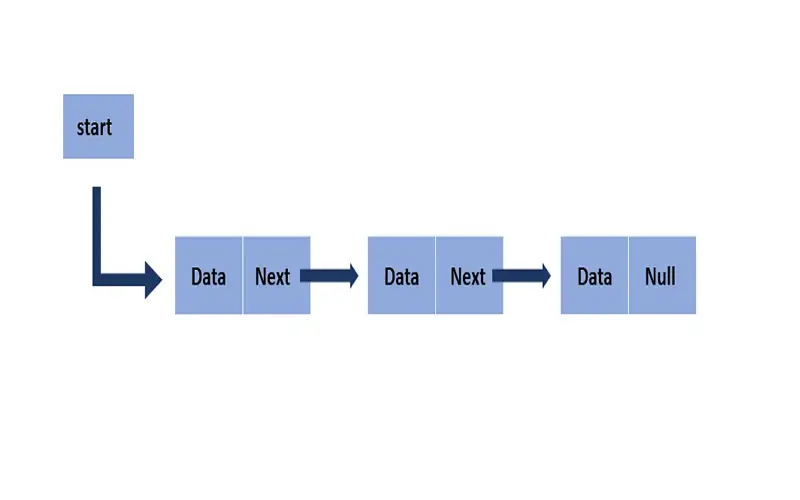
Linked lists are any other essential statistical structure, forming a sequential chain of nodes. In this shape, each node comprises a fact element and a reference pointing to the subsequent node. Linked lists prove exceedingly helpful in scenarios where the number of features is uncertain or where frequent insertions and deletions play a significant role. Due to their dynamic nature and ability to deal with various sizes, connected lists discover substantial utility in information control structures, actual-time data processing, and situations where adaptability is paramount. This flexibility sets them apart as a favored desire over fixed-length arrays in scenarios wherein fact growth or exchange is anticipated. It emphasizes their imperative function in modern-day programming and set of rules design.
3. Stacks
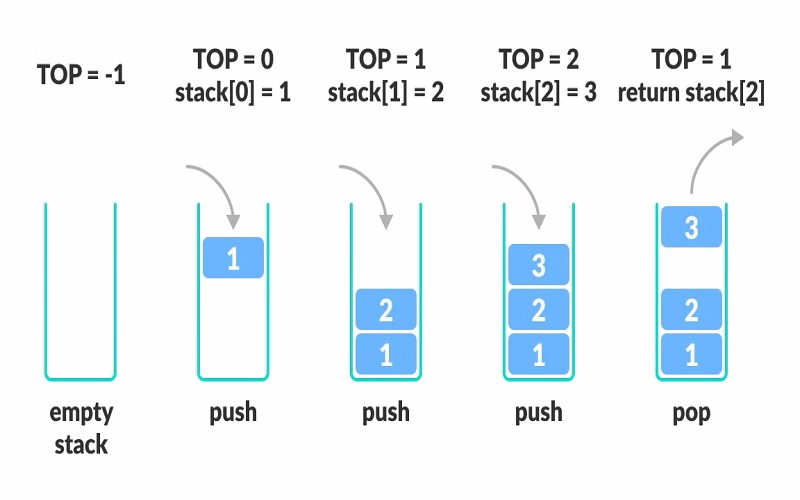
A stack is a virtual pile of gadgets that operates on the precept of last-in, first-out (LIFO). Imagine stacking books; the last e-book you put on top of the bank is the primary one you take off. Similarly, in a stack information structure, you may only add or take away gadgets from one give-up, known as the top of the stack. This simple concept finds extensive use in programming languages and PC technology. It enables the retention of features or techniques that can be energetic in software (like a call stack), evaluating expressions, and handling tasks like backtracking, where you must undo the ultimate movement and maintain it from there. Stacks provide a sensible way to manage and organize records, making them an essential device in software development.
4. Queues
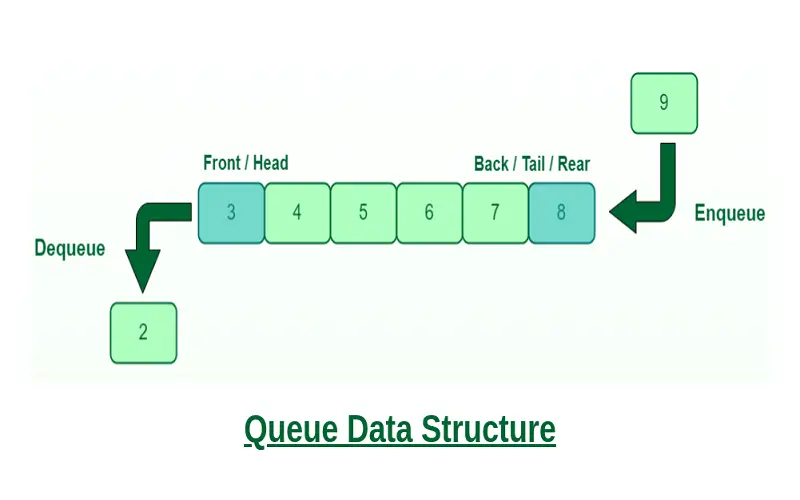
Queues are simple and essential data structures that work on the “first-in, first-out” (FIFO) principle. Imagine a line at the ticket counter. The person who enters first is the first to be served. Rows work the same way. You add items or elements to one end (we call it the back) and take things out from the other end (known as the front). They are like lines in everyday life: the person who came first gets served first. In the computer world, we use queues in situations where we need to keep track of how things are added. For example, think about scheduling tasks, handling requests, or finding the shortest path in a maze. That’s where the lines shine. They are like virtual lines that help computers manage operations efficiently and keep things fair and organized.
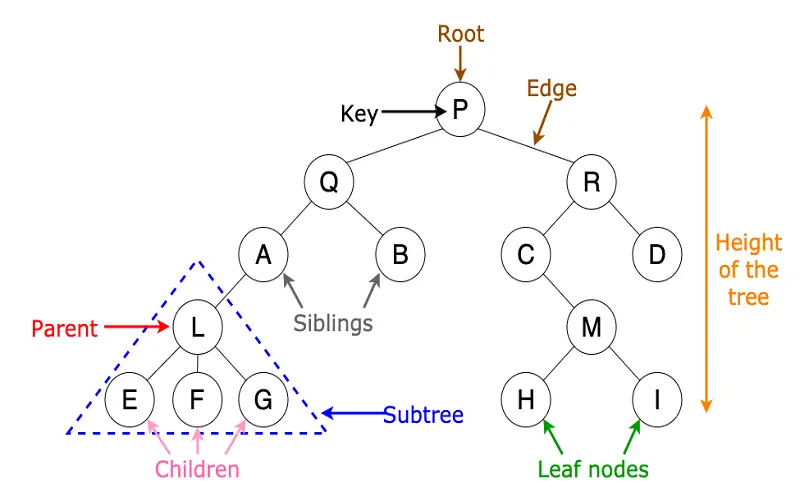
5. Trees
Trees are hierarchical data structures that contain nodes connected by edges. Each node can have several child nodes, creating a parent-child relationship. Trees are convenient tools for representing hierarchical relationships, as found in file systems, organizational charts, and decision-making processes. Their simple yet powerful structure enables us to organize data in a way that reflects natural relationships, making information easier to manage and retrieve. Trees are particularly suited to tasks where items have varying importance or when you need to break down complex concepts into simpler subcategories. This versatility and intuitiveness make trees an essential idea in computer science and day-to-day problem-solving.
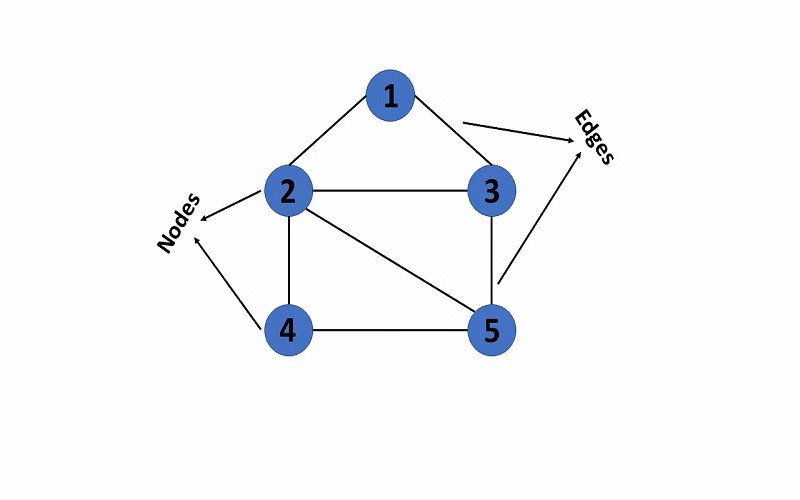
6. Graphs
Graphs act as elementary structures that contain nodes, also known as vertices, and edges connecting these nodes. They provide a versatile framework for depicting relationships between different organizations, and graphs can take on other characteristics to explore applications in various areas such as social networks, transport systems, and software dependencies. They may be directed, where the edges have a specific direction, or undirected, where the edges lack directionality. Furthermore, edges can have weights, indicating different connection degrees or costs between nodes, or be unweighted, treating all connections equally. This flexibility in representation empowers graphs to model complex relationships, and dependencies so that they are tough in the real world. They are an indispensable tool for tackling problems and informing decisions in areas ranging from computer science to urban planning.
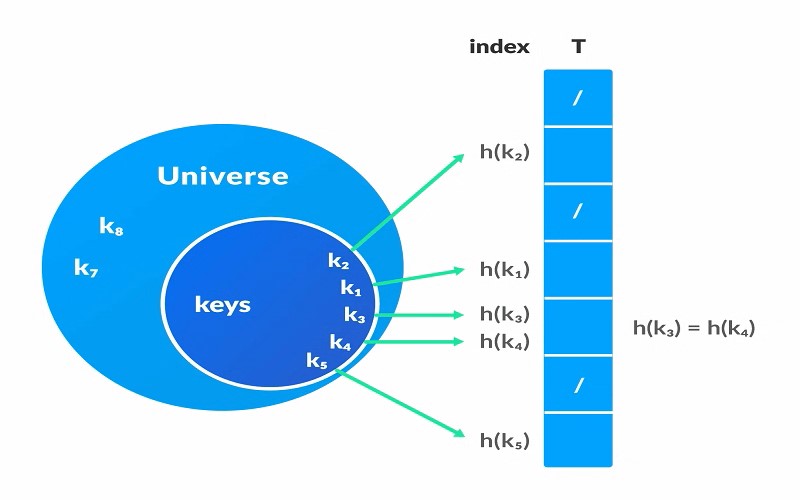
7. Hash Tables
Hash tables, often called hash maps, are data structures designed to store key and value pairs. These clever constructs employ hash functions to compute an index where the corresponding value is safely tucked away, ensuring fast and efficient data retrieval and insertion operations. Hash tables are gaining widespread popularity in applications requiring fast access to data, dictionaries, collections, etc. Finding their inevitable role in areas of massive databases and indexing their efficiency lies in their ability to quickly find out where data resides, making them invaluable in jobs that require quick access to information and keeping everything streamlined and accessible.
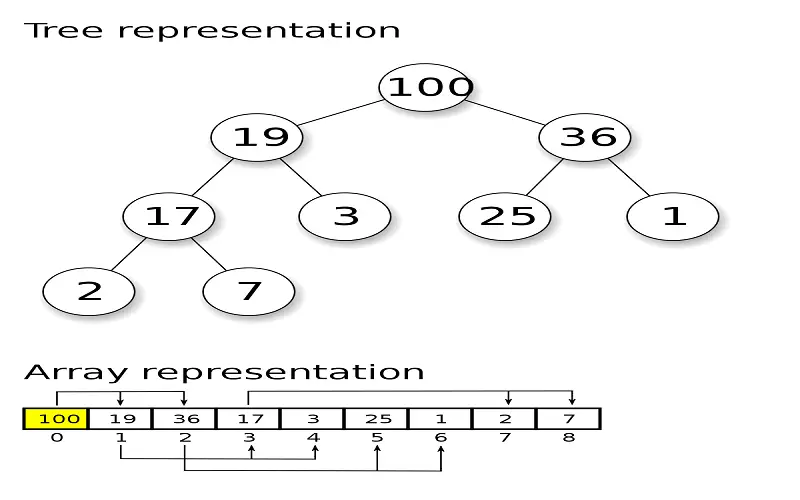
8. Heaps
Heaps are binary trees that obey a specific law known as the heap property. This property specifies that the value of each node must be greater than or equal to (or less than or equal to) the importance of its child nodes. Heaps play an essential role in computer science, especially in data structures and algorithms. Their primary application seems to implement priority queues, a data structure where the highest (or lowest) priority elements are removed quickly and efficiently. This unique quality of heaps makes them invaluable in tasks where fast access to critical data is essential. They enable efficient organization and retrieval of based information, simplifying complex problem-solving in different areas.
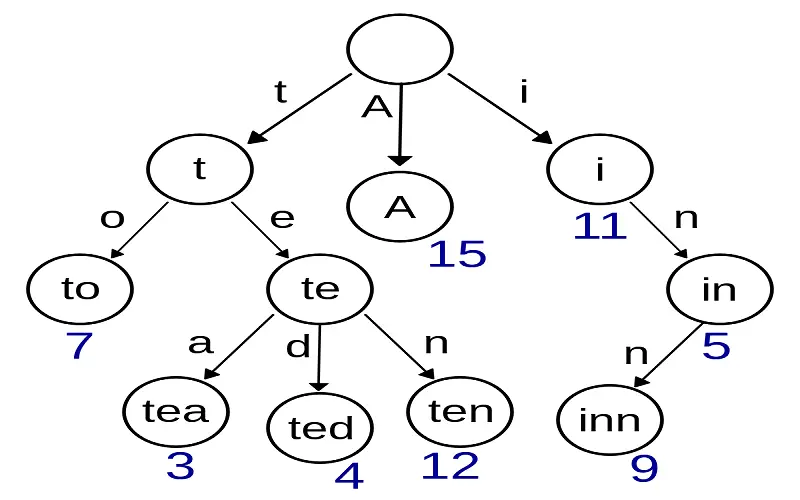
9. Tries
Trie, sometimes called prefix trees, are unique tree-based data structures specifically designed to store a collection of strings. Each node within Trie carries the essence of a prefix or entire word;those connecting edges embody individual characters in those strings. This specific architecture grants Trie extraordinary efficiency in various applications, such as autocomplete suggestion, spell checking, IP routing, and the complex task of finding words or parts quickly, making them invaluable where fast and accurate matching is essential. Tries are a vital tool in the toolkit of computer scientists and programmers, helping enhance the performance of diverse tasks that rely on efficient string handling and manipulation.
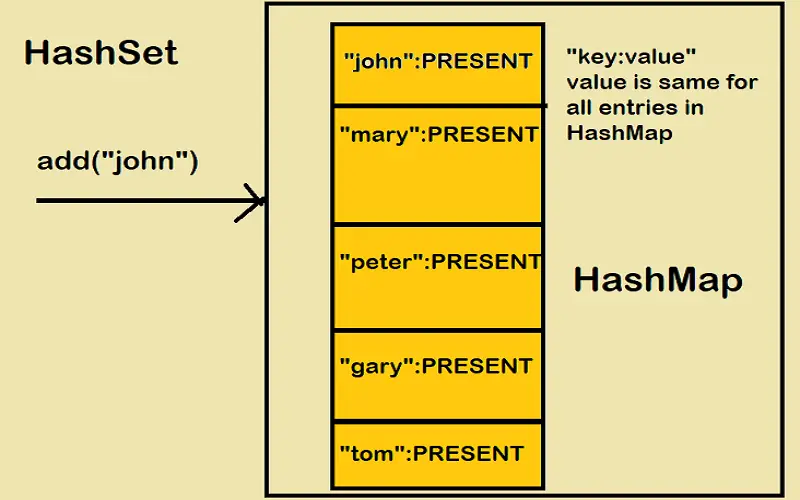
10. Hash Sets
Hash sets are data structures designed to house a collection of elements, ensuring that each component is unique. The magic behind hash sets lies in using a hash function, which calculates an index to store each piece. This clever mechanism enables fast insertion, retrieval, and deletion of features, making hash sets the go-to option when speed matters. Think of hash sets as the superheroes of data storage when it comes to tasks like ferreting out duplicates or conducting set operations efficiently and accurately. Think of hash sets at work as superheroes of data storage. These nifty structures are critial in optimizing data processing, whether you’re wrangling data in programming, handling database operations, or tackling day-to-day troubleshooting.















{kind=link}