
Introduction:
In 2001, autonomic computing was an idea of Jiming Liu, IBM and they took the initiative for it that aimed to make systems that can manage itself, in the era of complexity wall-block. The decision-making capability using high policies, the system itself fits to unpredictable situations. Autonomic components (AC) interacting with each other build an autonomic computing framework, which can be modelled in two main ways i.e. local and global with self-monitoring sensors, self-adjusting effectors, also this architecture is well-known as M-A-P-E (Monitor Analyse Plan Execute).
But what is exactly AUTONOMIC COMPUTING??
Autonomic computing is basically self-managing characteristics of computing resources that are distributed, fitting to incalculable changes while hiding intrinsic complexity from Users.
Before autonomic computing, the highly skilled humans used to adjust the computers as per the environment. But autonomic computing made it possible for characteristics to come true. There are four aspects that comprise of autonomic computing:
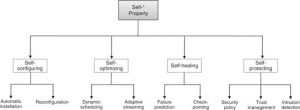
- self-optimization-Monitor, support, manage
- self-healing-detect, isolate, fix, reintegrate
- self-configuration-install, configure, integrate
- self-protecting-anticipate, detect, identify, Protect
Characteristics
- Automaticity
- Adaptive
- Aware
- Reflexivity
- Transparency
- Open Source
- Autonomic and Evaluability
- Easy to train and learn
Self-managing systems change the IT business
Details of mechanics and IT processes are classified into 4 main functions:
- collect the data,
- analyse the details,
- create a plan of action and
- execute the plan.
- These four functions correspond to the
- monitor,
- analyse,
- plan and
- execute parts of the architecture

IBM has set forth eight conditions that define an autonomic system:
The system must
- Know itself in terms of what resources it has access to, what its capabilities and limitations are and how and why it is connected to other systems.
- Be able to automatically configure and reconfigure itself depending on the changing computing environment.
- Be able to optimize its performance to ensure the most efficient computing process.
- Be able to work around encountered problems by either repairing itself or routing functions away from the trouble.
- Detect, identify and protect itself against various types of attacks to maintain overall system security and integrity.
- The system must be able to adapt to its environment as it changes, interacting with neighbouring systems and establishing communication protocols.
- Rely on open standards and cannot exist in a proprietary environment.
- Anticipate the demand on its resources while keeping transparent to users.
Reasons, why autonomic computing became a question?
- Traditional grid resource management techniques did not ensure fair and limited access to resources in many systems.
- Traditional metrics like throughput, waiting time, slowness, etc. failed to capture the most suitable requirements of users.
- No incentives for users to be flexible about resource requirement or job deadlines.
- No provisions to accommodate users with urgent work.
Advantages
- It is capable of solving larger, more complex problems in a given time
- It collaborates with other organizations
- Make better use of existing hardware
Disadvantages
- Grid software and standards are still developing
- Standards are unstable
- Need to Learn the curve to get started
- Needs no interaction for job submission
Applications
IBM eLiza:
eLiza is IBM’s initiative to add autonomic capabilities into existing products such as their servers.
An autonomic server is enhanced with capabilities such as:
- The detection and isolation of bad memory chips, protection against hacker attacks.
- When new features are added, it automatically configures itself.
- Optimizing CPU,
- Storage and resources to handle different levels of internal traffic.
More applications:
- Application partitioning that involves breaking the problem into discrete pieces.
- Discovery and scheduling of tasks and workflow.
- Data communication is distributing the problem data where and when it is required.
- Provisioning and distributing applications codes to each system nodes.















{kind=link}