
Reinforcement studying is the schooling system studying fashions to make a series of decisions. The agent learns to reap an intention in uncertain, probably complicated, surroundings. In reinforcement studying, synthetic intelligence faces a game-like situation. The PC employs trials and blunders to provide you with an option to the trouble. To get the system to do what the programmer wants, the synthetic intelligence receives both rewards and consequences for the movements it performs. It intends to maximize the overall praise.
1. How Does Reinforcement Learning Work?
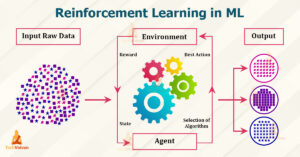
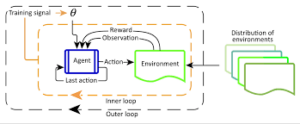
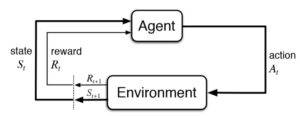
The Reinforcement Learning trouble entails an agent exploring unknown surroundings to reap an intention. RL is primarily based totally on the speculation that everyone’s dream may be defined through the maximization of anticipated cumulative praise. The agent needs to learn how to experience and perturb the kingdom of the surroundings the usage of its movements to derive maximal praise. The formal framework for RL borrows from the trouble of most appropriate manipulate of Markov Decision Processes (MDP).
The primary factors of an RL gadget are:
- The agent or the learner
- The surroundings the agent interacts with
- The coverage that the agent follows to take movements
- The praise sign that the agent observes upon taking movements
2. Benefits of Reinforcement Learning
Reinforcement studying is relevant to an extensive variety of complicated issues that can’t be tackled with different system studying algorithms. RL is in the direction of synthetic trendy intelligence (AGI) because it possesses the capacity to are looking for a long-time period of intention even as exploring numerous opportunities autonomously. Some of the blessings of RL include.

3. Focuses on the trouble as a whole
Conventional system studying algorithms are designed to excel at particular subtasks, without a perception of the large picture. RL, on the alternative hand, doesn’t divide the trouble into subproblems; it immediately works to maximize the long-time period praise.

4. Does now no longer want a separate statistics series step
In RL, schooling statistics are received thru the direct interplay of the agent with the surroundings. Training statistics are the studying agents enjoy, now no longer a separate series of statistics that needs to be fed to the algorithm. This substantially reduces the weight of the manager in the fee of the schooling process.
5. Works in dynamic, unsure environments
RL algorithms are inherently adaptive and constructed to reply to modifications withinside the surroundings. In RL, time topics and the enjoy that the agent collects aren’t independently and identically distributed, in contrast to traditional system studying algorithms.
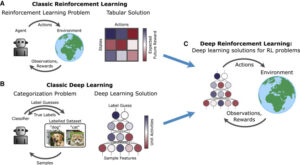
6. Reinforcement studying from deep studying and system studying; the difference?
There must be no clean divide among system studying, deep studying, and reinforcement studying. It is sort of a parallelogram – rectangle – rectangular relation, in which system studying is the broadest class and the deep reinforcement studying the maximum slim one.
7. Is reinforcement studying the destiny of system studying?
Although reinforcement studying, deep studying, and system studying are interconnected no one in all they especially go to update the others. Yann LeCun, the famend French scientist and head of studies at Facebook, jokes that reinforcement studying is the cherry on an exquisite AI cake with a system studying the cake itself and deep studying the icing.

Challenges with reinforcement studying
8. RL agent wishes large enjoy
RL strategies autonomously generate schooling statistics through interacting with the surroundings. Thus, the charge of the statistics series is restrained through the dynamics of the surroundings. Environments with excessive latency gradually down the studying curve. Furthermore, in complicated environments with excessive-dimensional kingdom spaces, large exploration is wanted earlier than an amazing answer may be found.
9. Delayed rewards
The studying agent can change off short-time period rewards for long-time period gains. While this foundational precept makes RL useful, it additionally makes it hard for the agent to find out the most appropriate coverage. This is mainly genuine in environments in which the final results are unknown till a huge variety of sequential movements are taken.
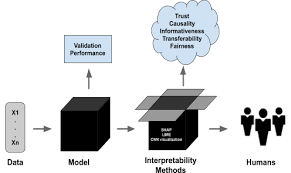
10. Lack of interpretability
Once an RL agent has discovered the most appropriate coverage and is deployed withinside the surroundings, it takes movements primarily based totally on its enjoyment. To an outside observer, the motive for those movements won’t be obvious. This loss of interpretability interferes with the improvement of considering among the agent and the observer.
11. What’s the Future of Reinforcement Learning?
In latest years, considerable development has been made withinside the region of deep reinforcement studying. Deep reinforcement studying makes use of deep neural networks to version the cost function (cost-primarily based totally) or the agent’s coverage (coverage-primarily based totally) or both (actor-critic). Before the enormous achievement of deep neural networks, complicated capabilities needed to be engineered to teach an RL algorithm. This supposed decreased studying capacity, restricting the scope of RL to easy environments.

Conclusion
The key distinguishing thing of reinforcement studying is how the agent is trained. Instead of analyzing the statistics provided, the version interacts with the surroundings, in search of methods to maximize the praise. In the case of deep reinforcement studying, a neural community is in fee of storing the stories and as a result, improving the manner the project is performed.















{kind=link}