
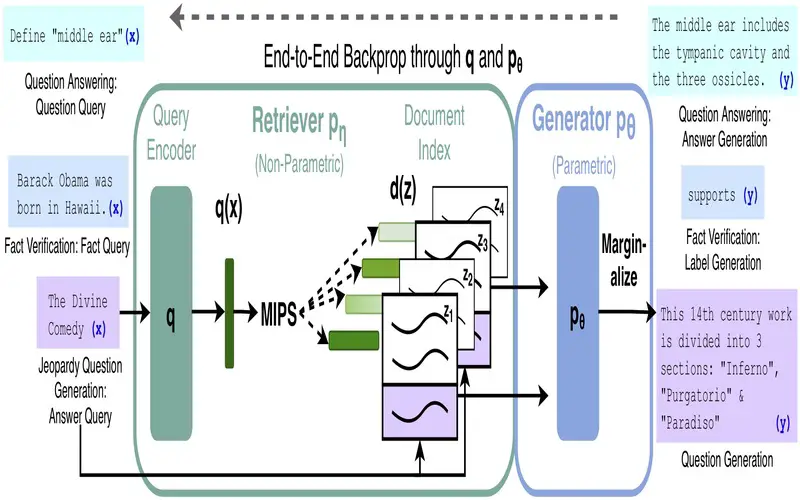
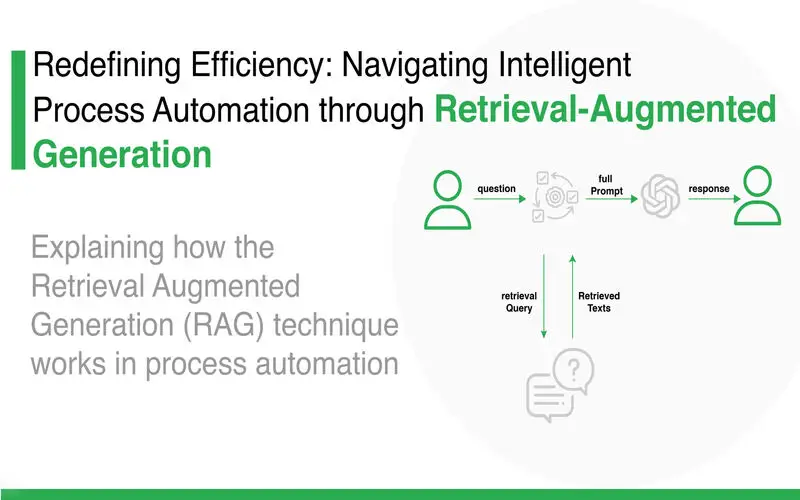
What Is Retrieval-Augmented Generation?
RAG is an AI structure for regaining facts from an external knowledge base to ground large language (LLMs) on the most correct, updated details and to provide consumers insights into LLMs’ generative process.
Retrieval-augmented generation (RAG) is an AI structure for enhancing the quality of LLM-generated reactions by grounding the model on the exterior sources of knowledge to supply the LLM’s internal representation of information. Executing RAG in an LLM-based question- responding system has two main advantages: It ensures that the most current, flexible facts, and that have consumers access to the model’s sources, ensuring that its claims can be verified for evaluation and ultimately trusted.
How Does Retrieval-Augmented Generation (RAG) Work?
The functionality of retrieval-augmented (RAG) is bonded in a complicated process that consistently combines retrieval and generation procedures to organize a cohesive, comprehensive, and dependability-related content creation process. The operational structure of RAG includes two cardinal stages:
- Information Retrieval: in these stages, the AI model manipulates tough retrieval mechanisms to access and integrates information from disparate sources, including a various array of structured datasets. Its retrieval process serves as the foundational bedrock, furnishing the successive content generation stage with a rich restoration of provisional knowledge.
- Natural Language Generation: following the retrieval stage, RAG carefully assimilates the retrieved information, flowing and synthesizing it into consistent structured and contextually informed content, this stage outlines the dexterous, blending of retrieved knowledge with verbal adeptness, culminating in the generation of content that resonates with context, related and informativeness.
Advantages Of Retrieval-Augmented Generation
RAG methods can be pre-owned to enhance the quality of a generative AI system’s answer beyond what an LLM alone does. Benefits involve the following:
- The RAG methods have access to information that may be fresher than the data used to train the LLM.
- Data in the RAG’s knowledge restores can be consistently updated without causing significant costs.
- The RAG’s knowledge restored can consist of data that’s more background than the data in a generalized LLM.
- The source of the information in the RAG’s vector database is recognized. And because the data sources are known, incorrect information in the RAG can be modified or deleted.
1. Access To Extensive Knowledge
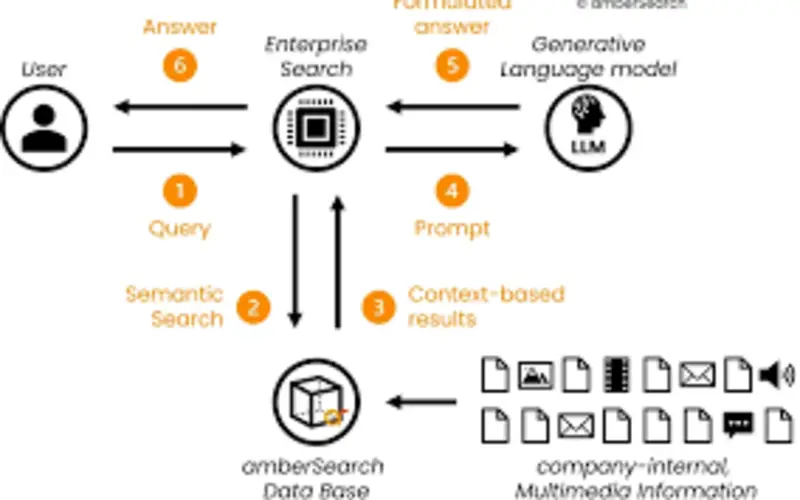
RAG can access a wide amount of information for a knowledge base. It enables it to create responses based on updated information, creating it singly efficiently for duties that require access to current data. Rag enables static LLMs with outdated training data to access the latest or specialized information.
2. Improved Related
By merging retrieval and generation models, RAG can manufacture responses that are more contextually related. It retrieves information relevant to the input occasion and uses these details to create a response, resulting in outputs that are more correct and related to the consumer questions.
3. Enhanced Accuracy
RAG enhances the correctness the accuracy of created responses by retrieving related documents from its non-parametric memory and using them as surroundings for the generation process. It conducts responses that are not only dependently accurate but also factually correct. RAG regain related documents from its memory and uses them as surroundings for the generation process. It conducts reactions that are surroundings accurate and factually correct.
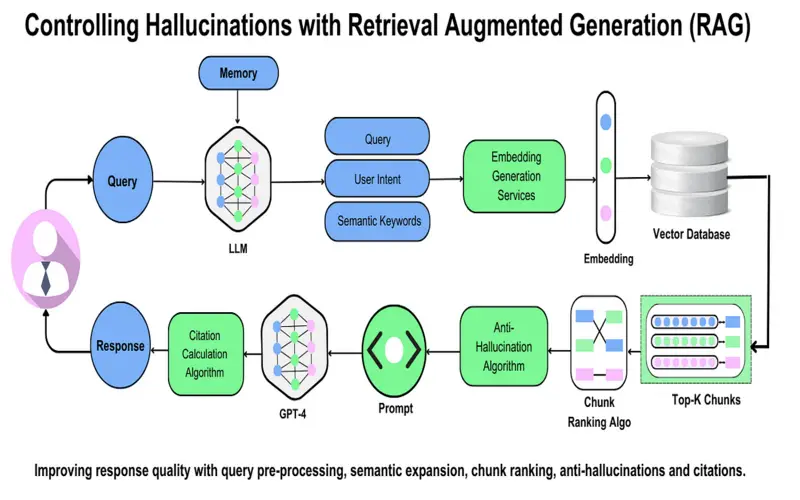
4. Reduced Hallucinations
RAG minimizes hallucinations, which are examples where the model creates information that is not landed in reality or the offered context. By recovering and using related documents for a gain base, RAG ensures that the created responses are exactly correct and appropriate, therefore reducing the chances of hallucination.
5. Scalability
RAG models can be scaled up by maximizing the size of the knowledge base or by using more strong pre-trained language models. It makes RAG a reliable and scalable solution for a vast range of language generation duties.

6. Effectively
RAG bypasses the requirement for retraining generally needed by other models, allowing it to access the new information for creating flexible outputs between retrieval-based generation. It makes RAG an effective device for conditions where facts could develop over time.
7. Improved Model Performance
Actual-time phenomena deployed by RAG models assist created updated reactions aligned with consumer questions or input. By exploiting exterior knowledge sources, RAG models ensure the created content retains related to developing growth. Its ability improves the overall model performance by making it more reliable and trustworthy. Its optimized performance is helpful in various domains like journalism, research, and academics where exactness and timeliness are paramount.
8. Dynamic Details Retrieval
One of the most important benefits of retrieval-augmented generation is its capability to retrieve information during the generation process dynamically. Unlike standard language models that depend solely on pre-learned knowledge, RAG presents a dynamic element that enables the model to pull in the latest information based on the input question. Its dynamism is singly useful for applications or questions that contract with updated information such as actual-time flight booking, weather updates, or life scores.
9. Cost-Effectively
Retrieval-augmented generation provides greater cost effectively than the conventional LLMs. Standard language models can be resource-detailed due to the required for extensive training on wide datasets. RAG, exploits pre-existing models and merges them with an information-retrieval system. It reached minimizes the need for additional training and fine-tuning, saving essential computational resources. The end-to-end RAG training evaluates the retrieval and generation process simultaneously to make the model more effectively. The computational and financial costs of retraining FMs for managing or domain-certain information are high. RAG is a more cost-efficiently reached to introducing new data to the LLM. It makes create artificial intelligence innovation more broadly available and usable.

10. More Developer Control
With RAG, programmers can test and enhance their chat applications more effectively. They can organize and convert the LLM’s information sources to adapt to converting requirements or cross-functional usage. Programmers can also regulate sensitive information retrieval to distinct accessed stages and ensure the LLM creates appropriate reactions. In addition, they can also troubleshoot and make fixes if the LLM references incorrect details sources for certain questions. Management can execute create AI innovation more confidently for a boarder range of applications.















{kind=link}