
Clustering
Clustering or cluster analysis Is a technique of inspection in free learning and method of data analysis in general statistics used in many fields of science as well as commerce such as bioinformatics, genomics, sequence analysis, ecology, image analysis, etc. It is defined as a process of gathering objects into groups or cluster by maintain similarity.
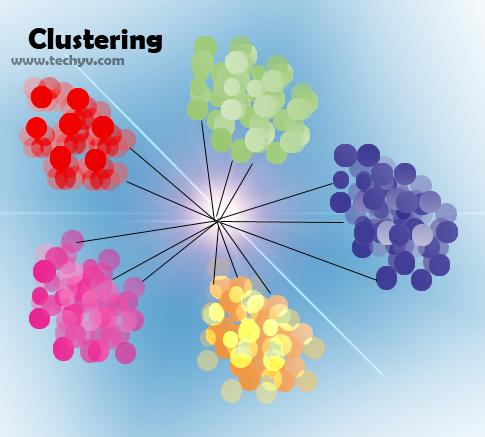
In a cluster, objects should have similarities by means of some properties or characteristics such as distance, size, mass, color or some other specification. Dissimilar objects belong to different cluster. Thus we can say perspective of clustering is to create homogenous groups in a set of unbalanced or unlabeled data. For example in our personal computer we keep a drive for music files, another drive for video files, a drive for software or programs while partitioning so that we can find desired file easily next time when needed. This is clustering.
Clustering algorithms can be applied in many field such as marketing by grouping customers data, biology by classifying plant & animal according to their features ,libraries by book ordering, earthquake studies by observing epicenters and identify risky zone. The algorithm should have scalability & order to deal with odd types of attributes. It should have aptitude to deal with din & outliers and find out clusters with random shape. A least prerequisite for domain data to decide various input parameters.
The algorithm should be high dimensional, interpretable and usable. Algorithm may classify as exclusive clustering, overlapping clustering, hierarchical clustering and probabilistic clustering. In the first way if a certain data belong to a specific cluster, it should not included in another one. The second type uses fuzzy set so that one data belongs to two or more cluster. The Hierarchical clustering is based upon the combination between two nearest cluster. And the last kind is entirely probabilistic approach.
For every corporate company their terms of rules ®ulation are very important. The information about its employee, their behavior, activities all should be maintained & managed. Their resource, capital, funding, marketing, finance, sales, service etc are also very important issue. Customers are the most important and sophisticated part for every company. Companies are bound to study the behavior of their customers. Bound to know who are customer, what they buy, what they want. All these information can be gathered & managed easily by means of clustering.
Clustering algorithms can be applied for finding similar group of customer with their interests, properties and records and thus provide a large database on customer’s data which provides direction for a company to determine their marketing policy. As for example, it is observed by clustering consumers according to their attitudes on corporate social liability underscore that customers consider that the corporate social liability have a great importance in business and they are tend to prize socially liable companies and punish socially hasty companies. Consumers who had affirmative approach toward socially liable companies were segmented in terms of behavioral issue.
Also share holders inspect a company before, during & after their investment. It has been observed that corporate failure often caused by practicing bad commercial governance, so the demand of neat & superior commercial governance becomes greater in current times to get public poise. Though corporate transparency has been practiced by many companies, corporate governance should be a greater concern. That’s why a general algorithm is proposed for developing to categorize the companies according to their corporate governance system automatically.
There has many server to manage database such as Windows server, SQL server, SQL Azure, oracle etc.
For example, Windows Clustering Services of Microsoft’s Windows Server 2003 has designed to meet the higher demand for great ease of access along with the increased spread of the full time accessibility. Windows Server of this edition clusters support eight processors and a highest 8 GB of RAM. Data amount may vary with changing edition. Administrators are able to supervise all the data or resources fit into the whole cluster from single MMC. Appropriately installed and configured cluster support continued operation during hardware failure, software failure. The Enterprise Edition & the Datacenter Edition supports 8-node clusters. Where the previous editions support 2-node or 4-node clusters only. A fully redesigned wizard permits to link and add nodes to the cluster. If things go wrong it is possible troubleshooting by outlook logs and facts.
The Terminal Server directory service can also be configured for failover. It is not need any more to run the comclust. exe on every node. The advantage of the 64-bit version of Windows Server 2003 allows in clustering, which is very much important to optimize SQL Server Enterprise Edition. The others have also so many particular specification and reasons for choosing them. The web cluster uses load corresponding to send website visitors desires to existing servers. When a server fails, it is by design removed from the existing server’s group and visitors are sent to servers able to serve the function of web sites. Due to load sharing among multiple servers it is possible to decrease the required possessions on each server and recover the piece for end users. Firewall system can also be customized to fit exact needs.
The seminal paper on parallel processing also known as Amdahl’s law published in 1967 by Gene Amdahl of IBM considered as the base of cluster computing. The Packet switching networks were made-up in 1962 by RAND Corporation. By using this concept in 1969, the project named ARPANET created the first net based computer cluster by link up four computer centers which next grew into internet. The OS called Hydra was built in 1971 for a cluster of DEC PDP-11 minicomputers. First commercial product for clustering was ARC net, developed in 1977 by Data point.
But it was not commercially successful. Clustering became took place after VAXcluster released by DEC in 1984 for the VAX/VMS operating system. Above two products supported parallel computing as well as joint file systems and secondary devices. Another two early saleable product were the Tandem Himalaya what was a circa 1994 product and the IBM S/390 Parallel Sysplex. Second one is also a circa 1994, but for business purpose mainly.








")






{kind=link}