
Where did you put that file exactly?
An introduction to Storage Area Network
Every business needs it: it doesn’t matter which industry, country or even planet you are located in. In any economic exchange, we are bound to make use of information. It is the one universal currency.
Books were kept by Sumerian shopkeepers, and the tradition will last so long as we have shops. Of course, accountants prefer to do it by computer rather than little knots on strings, but information, however computed, is still integral to any business. Most of it is routine data, but bits of it, like Coke’s recipe, can make or break a company.
So a modern firm that wants to deliver results in a timely and accurate fashion has to make sure its employees gets to access information in likewise manner. The technology of managing and securing information on business IT platforms has now become both lucrative and essential. In this article, we will take a look at its most recent manifestation: the Storage Area Network (SAN).
1. What is SAN?
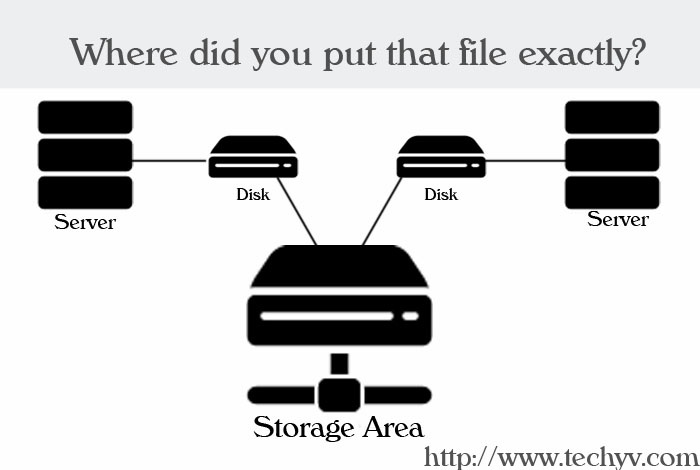
On the surface, the technical definition of SAN is so vague as to be all-encompassing. According to the Storage Network Industry Association, any network which is primarily responsible for data transfer between computers and storage qualifies as one. You have the physical wires, a management software layer, and the two bunches of nodes. Usually data is transferred on a block basis, as opposed to a file one, but we’ll come to that later.
What’s new about that? Most firms have an Ethernet backbone for Internet or Intranet access. And network drives (those pesky z:/, h:/ things on Windows) have been around for two decades. The principal difference lies within the specialization.
When we talk about storage devices, we inevitably think of a thumb-drive (if you’re a typical user) or a RAID or tape backup (if you call yourself an IT operative). They are both reliant on a dedicated connection between the computer and the device, and so the former effectively owns and manages the latter.
In a SAN environment, we keep all those different servers, but pool their storage resources into one. They are wired together with a similar architecture as that of local area networks (LANs): routers, hubs, gateways and the like. Provided that management grants the corresponding rights, any server can access the pool regardless of its physical location.
(If you think all this sounds familiar, it is because SAN is firmly rooted in IP networks. The new architecture is called Fiber Channel, and it uses two protocols: FICON for z/OS systems, and FCP for open source ones. As with LAN, SAN connects storage interfaces together into myriad configurations. Just to complicate things, even though SAN shares much of the terminology with IP networks, occasionally IBM comes up with new terms for the industry. The fact that the industry already has a term for it is an irrelevant point.)
The wiring matters. An optimized connection improves both performance and availability, as a single episode of disk failure would amply attest. There are also new modes of data transfer, which can go around the usual suspects for network sluggishness: bottlenecks. Originally we had the servers directly attached to storage devices. Granted, a single instance of the latter can be accessed by multiple servers. At the same time, however, SAN allows direct communication between servers, as well as that between storage devices.
Why would one storage device want to talk to another, if there’s no computation taking place? Mirroring is usually done for two reasons: optimizing performance, and backing up. This operation used to require a server making requests and supervising data integrity, but now it has been delegated to the SAN, freeing server resources in the process. Multiple servers can now talk with multiple storage devices.
Already we can see many potential benefits of this mode of operation. Storage is now wholly separate from both applications and the servers they run on, but more accessible from disparate data paths. With everything centralized, both storage management and data security measures have been simplified.
2. Why switch?
So in short, we have an externalized storage which is centralized in management but distributed across the firm. The management and cost benefits are clear enough, but what’s wrong with things as they stand?
Everything. For example, try to upgrade something. While it is simple enough to swap your computer hard disk for a bigger or faster one (you just mirror your data), a company intent on making products and hopefully money cannot risk this maneuver. Have you even tried to figure out how much you’ve paid per gigabyte? It’s borderline impossible if you have purchased the entire system, storage and all, from a vendor. You might splash out for shiny new devices, but what about accessibility, especially when every data transfer is already grinding to a halt before you install them? And are they reliable enough? How do you manage it all?
If you run a distributed storage environment, it is likely that you will face a multitude of platforms, each chosen to meet a specific application need. Sharing free capacity amongst them is a horribly complex maneuver, on par with that of sharing data itself. Frequently you’ll have to resort to duplication, if you are unwilling to sacrifice performance and availability for critical data. But you’ll have to track all the changes made to individual copies lest they spawn into a million different versions and gobble up your space.
Disk capacity has grown exponentially in the past decade, but input-output processes haven’t really kept pace. With tape backup via Ethernet you can expect no more than 8 MB/sec, which isn’t really a lot when the typical departmental database can grow to hundreds of GBs. But you can’t do it during office hours, because everybody’s terminal will grind to a halt.
This piecemeal approach simply breaks down in the face of new challenges, and it is high time we start from scratch. Behind every good storage solution is a good blueprint. And of course, it helps if the architecture you bought give you room to draw up one. It all comes down to servers. You find yourself amidst in abundance of server platforms, and as many standards to boot. Of course, the second part of that sentence is an oxymoron. The point of standards is that you’ve got one that works across platforms.
Happily, SAN vendors came to their senses early on before a Betamax war erupted. This is because storage is already an integral component of virtually all business platforms, and transitioning to a single vendor just for the sake of SAN benefits is prohibitively expensive. Acceptance of SNIA standards is widespread, and you can expect at least basic interoperability across platforms and vendors. They are even generous enough to test this aspect, and loudly certify any positive results to reassure the paranoid customer.
Early adopters beware, however. While the basic protocols were standardized quite early on, the rest of the high-level operations might clash because they are more likely to use proprietary elements. (How else can you differentiate your product?)
3. What can I expect?
So you’re an end-user. What do you actually see when you access a SAN? Hopefully nothing. The whole point of SAN is that the externalization happens behind the scenes.
Back in the olden days, we had the virtual hard drives. It is dedicated to a particular server or user, who sees it as a local drive. This behavior prevented multiple concurrent sharing of access, because it is a non-trivial problem of assigning whom to write to a file without corrupting it in the process. Of course, you could approach this problem from the file perspective: fence the whole thing up while an individual is accessing it, while other users queue up. This is usually done via file-based protocols such as SMB or NFS, which clearly address the data as remote.
But what of very large or frequently accessed files, such as those that comprise a database? A SAN approaches data from the block perspective, which is a more fundamental unit of information from the hardware’s perspective. The architecture doesn’t deal with file systems, leaving them instead to other management components.
The ability to handle data on a block basis means that the server can boot up directly from SAN, which is a tremendous advantage when it comes to disaster recovery. If the hardware of a server is at fault, a replacement server can simply boot up with the same data while repairs are in progress. Of course, the very nature of SAN also helps in other ways. Your replacement server could be on another continent, since SAN supports Fiber Channel over IP (FCIP) and can leap across the Internet. The traditional SCSI layer can only hop 25 meters in comparison, which, as anyone who’s ever tried to move entire server racks can attest, isn’t very helpful.
4. An example
Let us look at a niche application for illustration. If you’ve stumbled into a cinema in the last decade, chances are you’ll have watched a film comprising entirely of computer generated imagery. Thanks to the plunge in processor prices, we now have major studios setting up huge server farms for rendering purposes.
No, they don’t need SAN. Or more precisely put, they know what they’re doing, and would have implemented magnificent storage solutions from the ground up. But the same evolution in hardware has also produced affordable digital photography equipment with a cinematic quality that rivals those of conventional film. Coupled with the advent of desktop video editing software suites, a rising number of independent film-makers are setting up minuscule studios.
So we have a small group of editors working on “prosumer” equipment: high-end computers that are designed for individual consumers. While each computer can handle the requirements adequately, the video files are still quite large by typical LAN standards. To access the entire raw footage file can be cumbersome or downright infeasible. Furthermore, storage allocation cannot be shared on-the-go, but requires the user to request time-consuming transfers on an individual basis. And since space is already unevenly distributed, it’s senseless to implement RAID in every computer, leading to howls of despair when disks eventually fail.
A SAN implementation in this circumstances can bring two big benefits. It centralizes storage without undue extra costs, and it gives user control over bandwidth. At times of peak usage, a first-come-first-served approach can drag down the work flow In a SAN, each individual node (user or storage) can be assigned a certain quota or priority, so that nobody’s work grind to a complete halt. Apple and Avid now design their video suites with such implementations in mind.
Conclusion
As with business platforms at large, SAN is still evolving. A lot of new technology has smuggled its way into the framework, making their peace with one another instead of vying for monopoly. One trend is certain: data will never walk alone again.
Since we’re dealing with solutions instead of technologies here, it helps to remind ourselves from time to time that businesses will come to expect a very different sort of data provision in the future. They will ask for much more connectivity, a scalable infrastructure that allows capacity increases, and an unhindered flow of data both within and without. The intensity of data requirements will not be limited to the media industry: for example, an online shop would find itself handling a considerable amount of graphics, simply because shoppers expect to see the goods.
In the same way you fill up your personal computer with countless clutter, as expectations are realized through upcoming SAN implementations, corporate users, and by extension, their customers will come to ask a lot more of computers without knowing it. Perhaps in a few years, your customer relations department will have to archive video-calls, or maybe your transaction database will be flooded with micro-payments. Future-proof is the key word here, because there is no telling how deep the memory hole goes.















{kind=link}