Error importing large CSV file to CUBRID
Asked By
30 points
N/A
Posted on - 01/07/2012

Hi guys, I need to import a bulk CSV file to CUBRID Database Management. Because the speed of the process is very low, I decided to download the CUBRID Migration Toolkit (CMT). Then, I opened the CSV file in MySQL.
The process took 30 minutes before it finished. I attempt to create a CUBRID table and then transmit it to a MySQL Database to CUBRID Database. When done with the transmission, the table is already indexed.
And now, when I am trying to run the Database, I keep getting an error shown below:
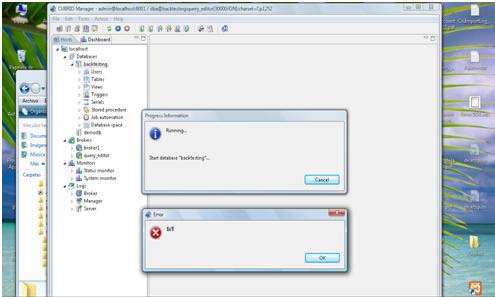
Progress Information
Running.
Start database "backtesting".










{kind=link}