
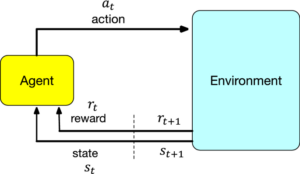
Deep Reinforcement Learning (DRL) has lately witnessed great advances that have brought about more than one success in fixing sequential decision-making troubles in numerous domains, in particular in Wi-Fi communications. The future sixth-generation (6G) networks are anticipated to offer scalable, low-latency, ultra-dependable offerings empowered through the utility of data-driven Artificial Intelligence (AI). The key to allowing the technology of destiny 6G networks, inclusive of smart meta-surfaces, aerial networks, and AI on the edge, contains multiple agents, which motivates the significance of multi-agent mastering.
1. Reinforcement Learning
This painting considers the hassle of getting to know cooperative regulations in complex, in part observable domain names without express communication. We make bigger 3 training of single-agent deep reinforcement getting to know algorithms primarily based totally on coverage gradient, temporal-distinction error, and actor-critic strategies to cooperative multi-agent systems. To efficiently scale those algorithms past a trivial quantity of agents, we integrate them with a multi-agent version of curriculum getting to know.

2. Bellman’s Background In Multi-Agent RL
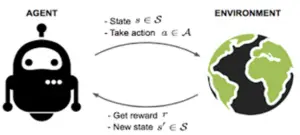
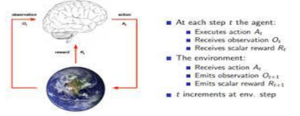
In this segment, we assess a consultant pattern of the literature. We begin with the algorithms, after which summarize the consequences reported. Throughout, we use the subsequent terminology and notation. An (n-agent) stochastic game (SG) is a tuple (N, S, A, R, T ). N is fixed of retailers listed 1,…,n. S is fixed of n-agent degree video games (typically notion of as video games in regular form, even though see [Jehiel and Samet2001] for an exception). A = A1,…, An, with Ai the set of movements (or natural strategies) of agent I (a word we expect the agent has the equal approach area in all video games; that is a notational convenience, however now no longer an important restriction). R = R1,…, Rn, with Ri: S × A → R the instantaneously praise characteristic of agent i.
3. From Minima-Q To Nash-Q And Beyond
We begin with the (single-agent) Q-mastering algorithm [Watkins and Dayan1992] for computing the greatest coverage in an MDP with unknown praise and transition functions:1
Q(s, a) ← (1 − α)Q(s, a) + α[R(s, a) + γV (s )]
V (s) ← max
∈A Q(s, a)
As is properly acknowledged, with sure assumptions approximately the manner wherein movements are decided on at every kingdom over time-mastering converges to the greatest price characteristic V ∗.
4. Convergence Consequences
The essential standards used to degree the overall performance of the above algorithms turned into their capacity to converge to an equilibrium in self-play. minimax-Q mastering is tested to converge within side the restriction to the right Q-values for any zero-sum game, ensuring convergence to a Nash equilibrium in self-play. These consequences make the usual assumptions of endless exploration and the situations on mastering quotes utilized in proofs of convergence for single-agent Q-mastering.
5. Why Attention To Equilibrium?
In the preceding segment, we summarized the trends in multi-agent RL without editorial comments. Here we start to talk about that paintings extra critically. The consequences regarding the convergence of Nash-Q are pretty awkward. Nash-Q tried to deal with general-sum SGs, however, the convergence consequences are confined to the instances that endure robust similarity to the already acknowledged instances of zero-sum video games and common-payoff video games. Furthermore, a word that the situations are in truth pretty restrictive, considering they should preserve for the video games described through the intermediate Q-values all through the execution of the protocol.
6. Four Properly Described Troubles In Multi-Agent Mastering
In our view, the basis of the problems with the latest paintings is that the sector has lacked an in reality described trouble statement. If (e.g.,) Nash-Q is the answer, what’s the question? In this segment, we discover what we assume is a coherent study schedule on multi-agent RL.
7. Pursuing The ‘AI Schedule’
The ‘AI schedule’ requires categorizing strategic environments, that is, populations of agent kinds with which the agent is designed may interact. These agent kinds can also additionally include a distribution over them, wherein case you’ll wish to layout an agent with a maximal anticipated payoff, or without this kind of distribution, wherein case a one of kind goal is known as for (for example, an agent with maximal minimal payoff).
8. Domain And Experimental Setup
Our area is an aid allocation negotiation scenario. Two retailers negotiate approximately the way to proportion resources. For the sake of clarity any more we can consult with apples and oranges. The retailers have one kind of goal.
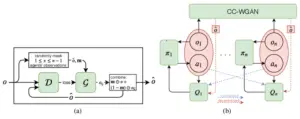
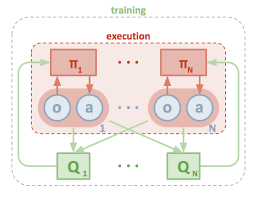
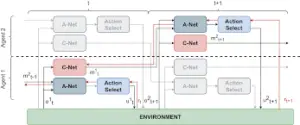
9. Stabilizing Experience Replay For Deep Multi-Agent Reinforcement Learning
Many real-global troubles, inclusive of community packet routing and concrete visitor’s control, are modeled as multi-agent reinforcement mastering (RL) troubles. However, present multi-agent RL techniques usually scale poorly within side the trouble size. Therefore, a key task is to translate the achievement of deep mastering on single-agent RL to the multi-agent setting.

10. Concluding Feedback
We have reviewed preceding paintings in multi-agent RL and feature argued for what we consider is a clean and fruitful studies schedule in AI on multi-agent mastering. Since we’ve made a few essential feedbacks of preceding paintings, this could supply the influence that we don’t recognize it or the researchers in the back of it. Nothing can be in addition to the truth.














{kind=link}