
‘Data’ is a term that one cannot neglect in the socially growing world. Every second we breathe, we are creating millions of data all over the world. Today, from the kids to the senescent, we can see every individual googling. According to the statistics, we are making about 40,000 searches for every second. This is the information about Google alone. It is a jaw-dropping fact to know the total amount of data being created in a day, it is 2.5 quintillion bytes of data. Storing, processing and accessing this big data, with the conventional tools like files, database etc. is tedious. There comes Hadoop to handle this big data.

HADOOP: An open source framework that handles large data sets in a distributed computing environment and runs on the cluster of commodity machines.
The genesis of Hadoop and its logo:![]()
It all started in 2003 with a research paper by google called Google file system (GFS) to store large amounts of data. Now we require some technique to process the data stored in this GFS. Then in 2004, Google published another paper to process the data- ‘Map Reduce’. But these two papers explain the techniques theoretically and no practically functioning model was provided. Doug Cutting, an employee of Yahoo made this possible. He created Hadoop based on the two research papers provided by google and introduced a new file system HDFS (Hadoop Distributed File System). The development was actually started with the Apache Nutch project and this was the outcome as a subproject of that. Hence, Hadoop is also known as Apache Hadoop.
Doug Cutting wanted to name it short, easy to spell, meaningless and not used elsewhere. He felt kids are good at creating such names. And Hadoop is a name given by his son to his small stuffed yellow elephant.
ARCHITECTURE:
A group of computers or nodes connected together and work as a single system is known as a cluster. A cluster used for Hadoop that handles unstructured data is defined as Hadoop cluster and runs on low-cost commodity machines. These clusters help in parallel processing in a distributed computing environment.
WHY DISTRIBUTED ENVIRONMENT?
Let us consider browsing in google. It must load the pages and produce the results as fast as possible so that it doesn’t test the user’s patience. Imagine if Google uses a single machine to store its data, then it takes pretty long to compute or process the entire data and produce the results. Instead, it becomes easy to scatter the data across a number of machines. This increases the processing speed and reduces the amount of data processing.

The architecture of Hadoop subscribes to a master-slave architecture. HDFS and Map reduce are the important components of Hadoop. There are 3 components in Hadoop cluster:
- Clients
- Master
- Slave
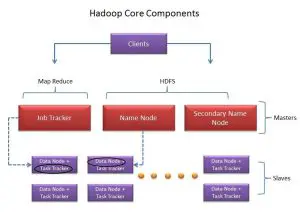
CLIENT:
The client is neither a master nor a slave. Its job is to load the data into clusters. It consists the client is neither a master nor a slave. Its job is to load the data into clusters. It consists of HDFS and map reduce.
The client is neither a HDFS: The file system used to store the large amounts of data. Its design facilitates fault tolerance and highly reliable. Blocks of data on different nodes are replicated so that even if one node fails the data is not lost.
- NAME NODE: The name node doesn’t contain the data but has metadata i.e. data about the data like information about namespaces, blocks of data etc. It is like a label to the cluster and regulates the user’s access to the files. It decides which data node to provide.

- MAP REDUCE: A processing technique used to process the data stored in HDFS. It is a programming model completely based on core java. It has two functions a) Map and b) Reduce. Mapping takes the data usually in form of files as input and generates a key-value pair list (example: Name is a key and marks is a value for that name). Reduce is an aggregation function that performs operations on the generated list (example: max of marks in the list).
- Job tracker: It schedules the jobs of the clients. It communicates with the name node to determine the location of data.
SLAVE:
DATA NODE: The actual data is contained in these data nodes. A data node is a slave to corresponding name node.
TASK TRACKER: It is a slave to the job tracker and functions on the data nodes. It receives tasks from the job tracker.
It is well and good if one is a pro in java in order to use map reduce to process the big data. But writing map reduce is not always easy and it is a problem when one cannot easily write them. So there come few tools that help to overcome this problem.
- HIVE:
Let us consider an example of searching for a person whose name is ‘x’ on Facebook. And it results in all the persons with that name using Facebook in less than 2 seconds. Map reduce plays an important role that can produce the results within a fraction of seconds. But unfortunately, almost all the employees of Facebook use SQL. It is not an efficient thing to transform the entire working staff with those who know map reduce. There comes a data warehouse infrastructure called Hive developed by Facebook. It provides a query language called Hive query language (HQL).
- PIG:
Pig is one of the productive tools introduced so far that can be used by those who are not well aware of any of the above languages. It was built by YAHOO. It is strange to hear a framework’s name as PIG but there is a reason behind it. How the animal pig can consume any type of food this tool pig was also designed to process any kind of data whether it may be structured, unstructured or semi-structured. PIG provides its own language called PIG Latin and it is a data flow language. Unlike Hive, Pig doesn’t keep up any metadata or warehouses. It just acts as an interface and one can process the data with it.

Hadoop has definitely changed the way data is processed or stored and has become a buzz word for over a decade. It has become a synonym of big data. It all started with HDFS and Hadoop but now consists of the hive, pig, hbase etc. There is no doubt that it lived to its fame of being the next big thing. Any new frameworks may come that supplement or complement this Hadoop, we must acknowledge the fact that this service application of big data, is the big thing now. This is Hadoop. “This” is now.















{kind=link}