
In the present world, all manual tasks are getting automated. It is an era of constant technological growth, and computing has become far more advanced than earlier. Scientists have put in a lot of effort in recent years and built sophisticated machines with advanced methods. These machines are replacing humans in several aspects as they focus on computers to think similarly to how humans do. Machine learning helps analyze data and patterns with minimum human intervention providing solutions to any problems. Today, machine learning techniques have advanced in multiple fields and industries. In this article, we will list the top 10 machine learning algorithms.
1. Linear Regression
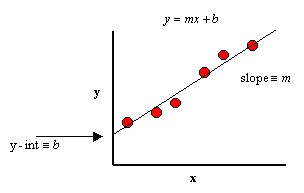
Linear regression is a mathematical representation of a linear equation that describes the relationship between input variables (x) and output variables (y). It is a well-known algorithm in statistics and machine learning. The equation for linear regression is: y = mx + b. Here a and b are coefficients where m is the slope of the line and b is the intercept (constant), y is the dependent variable, and x is an independent variable.
2. Logistic Regression
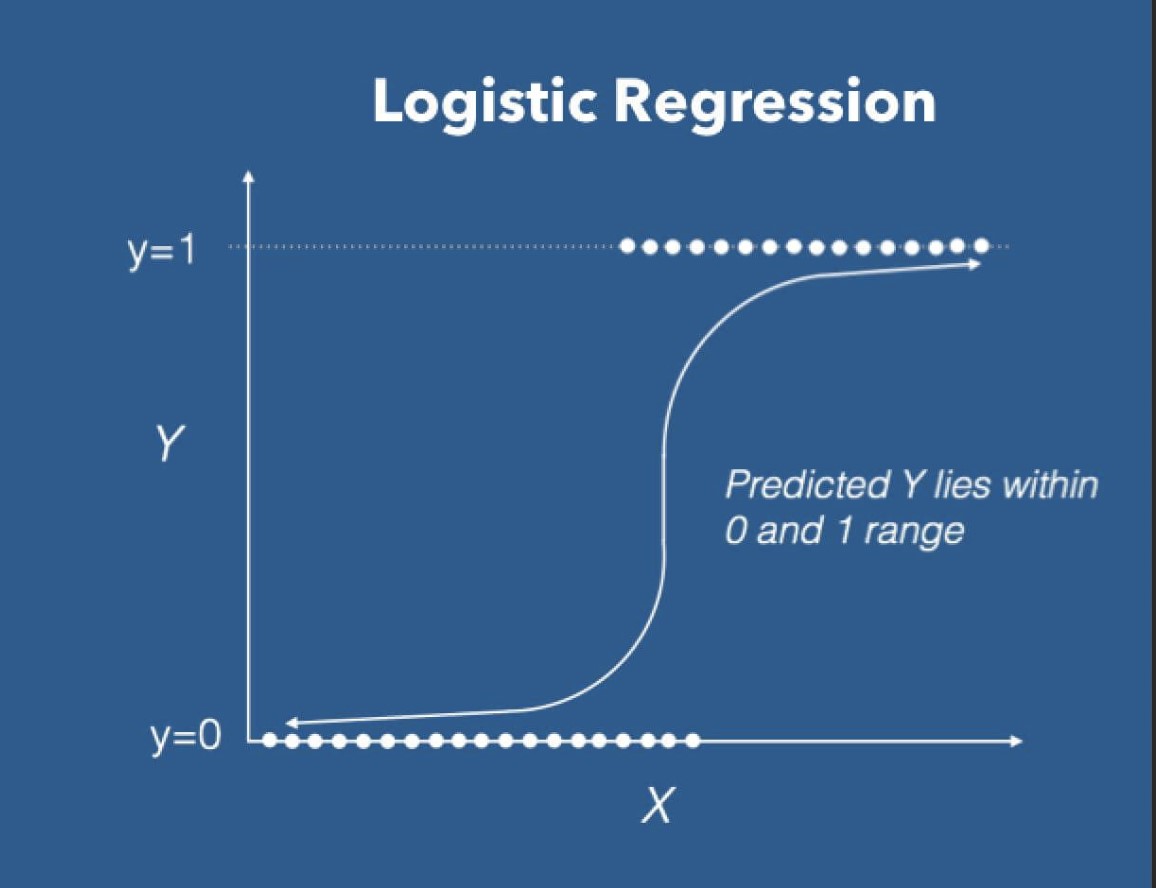
Logistic regression gives you predictions in the form of discrete values as binary data. Binary values are 0 or 1. For instance, for an event to occur, we have two possibilities. If the event takes place, the value is 1, else 0. It uses a transformation function, also called a logistic function. The equation for logistic regression is: h(x) = 1/ (1 + e^-x). The graph of logistic regression shows an exponential S-curve.
3. Support Vector Machine (SVM)
Support Vector Machine (SVM) is one best learning algorithms. It’s in use for both regression and classification. With this algorithm, you find a hyperplane in an N-dimensional space where you plot the data points. The dimension of the plane depends on the number of features (N). Hyperplanes help classify the data points. Support vectors are data points that influence the position and orientation of the hyperplane. These points build the SVM.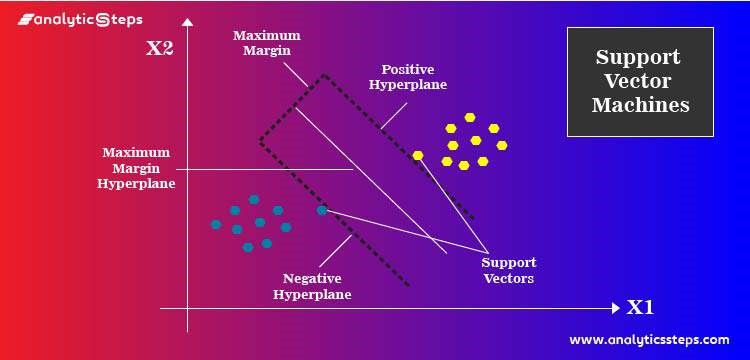
4. Naïve Bayes
The Naive Bayes algorithm uses the Bayes theorem to solve classification problems. The meaning of Naive is that the measurement features classified are independent of each other.
The formula of the Bayes theorem is:
P(A|B) = [P(B|A) P(A)]/P(B)
Here A and B are events
P(A|B) = Posterior Probability
P(B|A) = Likelihood Probability
P(A) = Prior Probability
P(B) = Marginal Probability
This algorithm is very effective on a wide range of complex problems.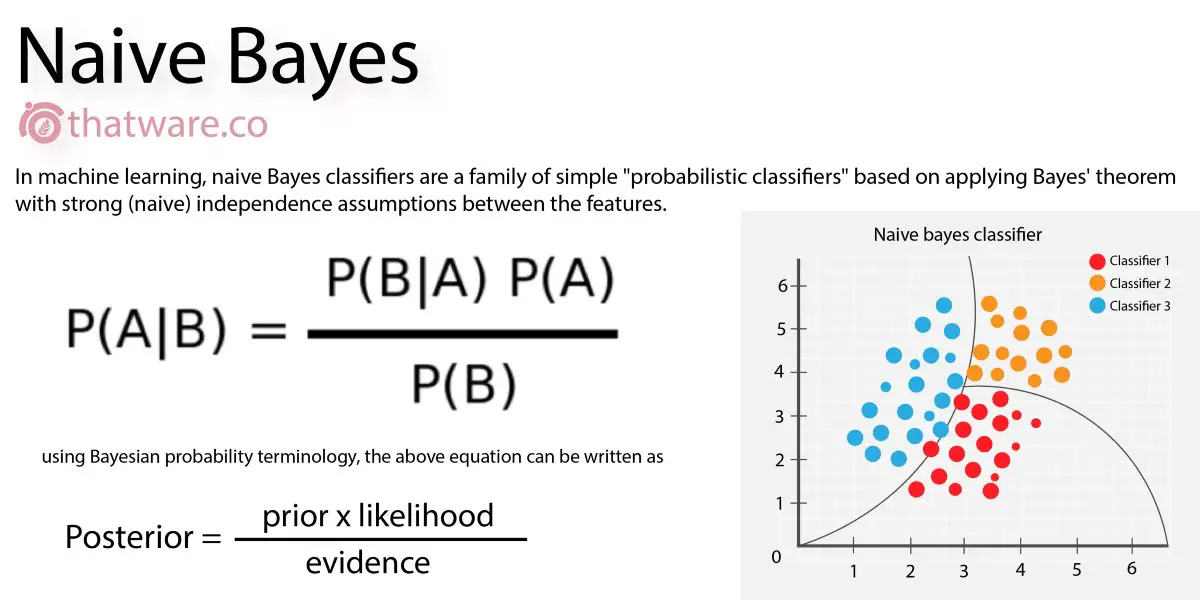
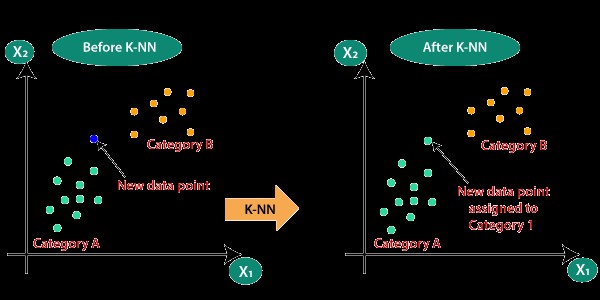
5. KNN (K – Nearest Neighbors)
K-nearest neighbors algorithm applies for regression and classification problems. It uses predictive analysis to predict the values of new data points (K nearest neighbors). The algorithm finds the K-nearest instances to the new one from the entire data set and gives the mean output for the problem. The predictions made by this algorithm are highly accurate. So, you can use it for applications that require high accuracy.
6. Random Forest
Random Forest is a flexible, easy-to-use algorithm for classification and regression problems. It is a collection of decision trees on various subsets of the given subset. The algorithm takes predictions from each tree, and from the majority votes, you get the final output. The higher the number of trees leads to the highest predictive accuracy of the dataset and prevents problems.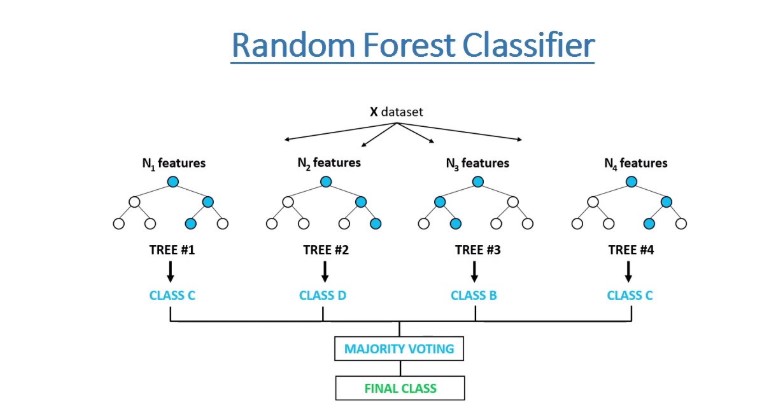
7. K-Means
K-Means is an iterative algorithm that solves clustering problems. The objective of the algorithm is to group the data into clusters. It calculates the K-centroids and assigns a data point to the one having the closest distance between its centroid and the data point. This computation goes on until you get the optimal centroid. Because of its simplicity, it’s one of the widely used clustering algorithms.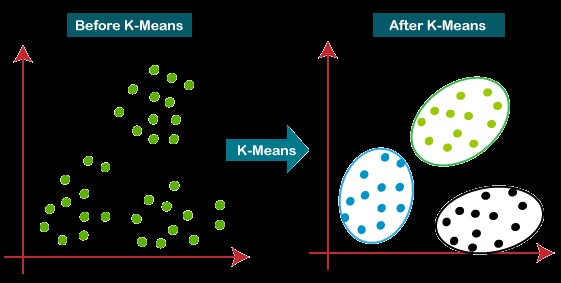
8. Boosting and AdaBoosting
Boosting is a method that helps to build a robust classifier from the number of weak classifiers. It handles massive loads of data to make predictions with high accuracy. You construct a model using delicate models in series. AdaBoost is the short form for Adaptive Boosting. It is a boosting algorithm for binary classification that combines multiple weak classifiers into a single one.

9. Learning Vector Quantization
The Learning Vector Quantization algorithm is an artificial neural network that looks like a collection of codebook vectors. They make predictions like K-Nearest Neighbor. You can find the best matching codebook vector by calculating the distance between each codebook vector and the new data instance. The class value for the best matching vector will be the final prediction. You can use LVQ to reduce the memory requirements of storing the entire dataset.
10. Linear Discriminant Analysis
Linear Discriminant Analysis is a classification algorithm used for feature extraction in pattern classification problems. It is a simple method but limited to two-class classification problems. The algorithm calculates a discriminate value for each class and predicts the highest value. LDA has its application in face detection algorithms to extract data from different faces.

Conclusion
The field of machine learning keeps growing and increasing, and the scope of machine learning tools provides solutions to complex world problems. It’s a good starting point in learning different algorithms to find an appropriate solution for the problem. So, try the above algorithms and evaluate the performance.















{kind=link}